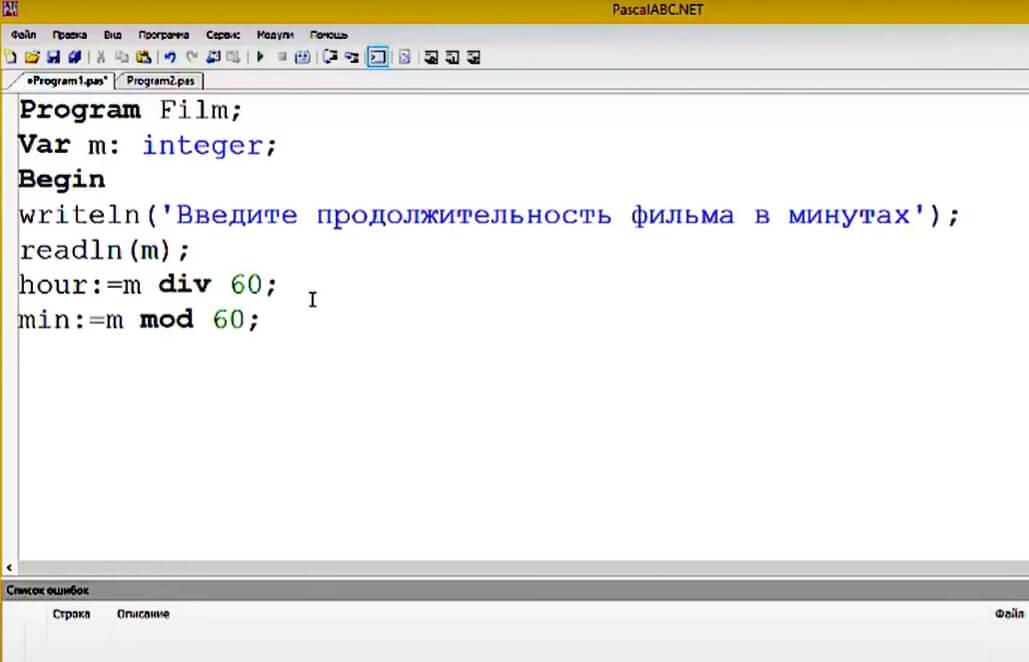
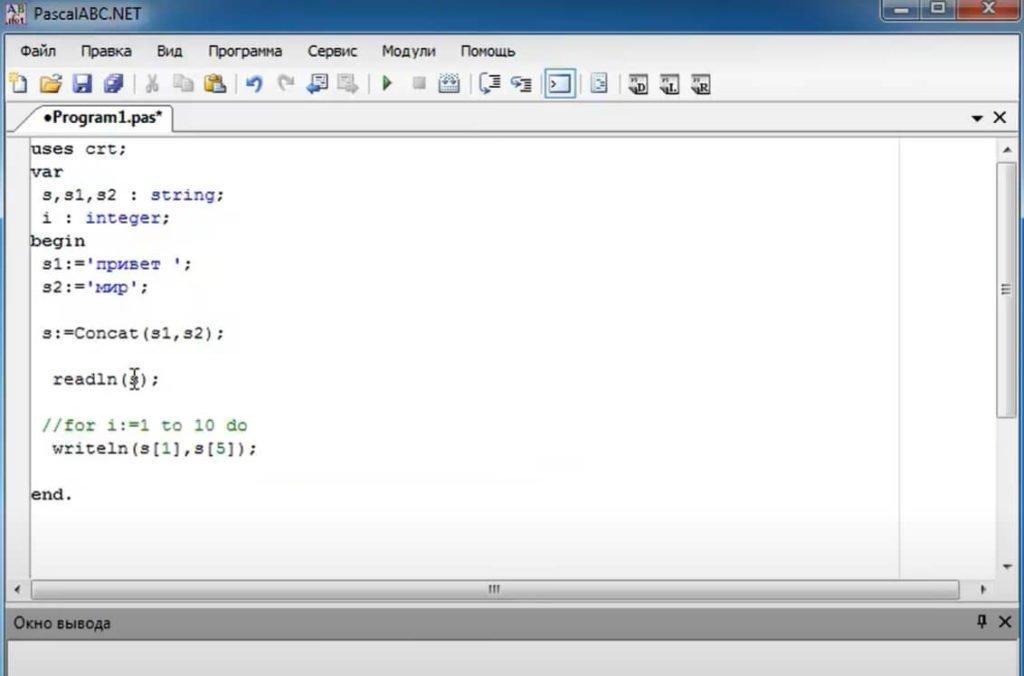
Строковый оператор в Pascal — string
String – тип представления данных, в котором значениями переменных выступают символы алфавита. Любая из переменных может быть как с определенным количеством байтов, так и совершенно разной длины.
Как тип представляется в памяти
Во многих языках программирования существуют максимальные значения размеров строк, в то время, как в других языках такого нет. Если же вы используете Unicode, то в нем каждый символ, относящийся к типу string, может занимать 2 или 4 байта для того, чтобы представить его.
Проблемы в представлении
Как и везде, тут выступают несколько недочетов в представлении данного типа данных:
- Каждая строка может занимать немалый объем (вплоть до многих десятков Мб);
- Неоднозначный размер, отсюда будут проблемы при редактировании текста.
Как относится к памяти компьютера
Есть два различающихся подхода, чтобы представить строку в памяти.
Массив
В данном подходе массив осуществляет представление компьютеру. Все размеры, при использовании данного способа, распределяются на разные области. Впервые такой подход был использован в языке Pascal, от чего получил название Pascal strings.
Такой метод устарел и был оптимизирован, получился формат caddr. Отличается он от Pascal strings тем, что массивы и их размеры выступают как частицы указания на определенную строку.
Преимущества:
В любое время программа будет иметь доступ к информации о размерах строк, благодаря чему многие действия будут выполняться намного быстрее;
- Возможность хранения различного типа данных;
- Предоставляется возможным отслеживание поведения строки;
- Операции на подобии “взять N-ый символ с конца” совершаются намного быстрее.
Недостатки:
- Обработка символов является проблематичной для строк произвольной длины;
- Большой объем выделенной памяти для хранения;
- Строки не имеют неограниченный размер. В более современных языках влияет не так сильно, потому что максимум может достигать до 4 гигабайт;
- Если вы будете применять алфавиты, имеющие изменчивый размер символов (UTF-8), будет храниться байтовый размер всех строк, а не количество символов в них, из-за чего его нужно считать независимо от размеров строк.
«Завершающий байт»
Второй метод подразумевает использовать конечный байт. Случайное значение какой-либо буквы или символа (обычно 0) будет использоваться в качестве конечной точки, а сама строка будет храниться в виде последовательности байтов. В некоторых системах значение символов берется 255 вместо нуля.
У такого метода есть несколько названий:
- ASCIIZ (значение 0 на конце);
- C-strings (наиболее популярен в Си);
- Ноль-терминированные строки.
Преимущества:
- Последовательность избавляется от служебной информации (не считая конечного байта);
- Ее можно представить, не создавая новый тип данных;
- Размер строки не ограничен;
- Разумное выделение памяти;
- Функции для передачи строк падают на начальный символ.
Недостатки:
- Более долго выполнение операций для того, чтобы узнать информацию о строке;
- Выход з максимальное значение не контролируется;
- При неполадках конечного байта может повредиться значительная область памяти (это, в свою очередь, способно привести к серьезному ущербу);
- Конечный байт, а точнее его символ, не может использоваться как часть последовательности;
- Невозможность использования определенных библиотек, в которых символ может занимать до нескольких байт (UTF-16).
Использование одновременно двух методов
Во многих языка, таких как Оберон, строка и представляется массивом, и конец ее имеет нулевой символ. Этот метод объединяет оба подхода, объединяя их преимущества и избегая много недостатков.
Какие бывают операции
Простейшие операции
В них входят:
- Использование индексов для нахождения символов по ним;
- Соединение одной последовательности с другой.
Производные операции
Включают в себя:
- Нахождение подстроки по номеру конечного и начального символа;
- Нахождение и замена подстроки;
- Не допустить повторение строк;
- Получение информации о длине последовательности;
- Свертка;
- Фильтр критерий для одних и тех же списков.
Более сложные операции
Подразумевают:
- Поиск самой маленькой надстроки;
- Поиск строк, которые совпадают в разных массивах;
- Задания с использованием естественного языка;
- Схожесть последовательностей по определенным критериям;
- Возможность определить кодировку, а также язык используемого набора символов.
Представление символов строки
В прошлые времена кодировка символов выглядела как 1 символ = 1 байт, то есть 8 бит (были случаи 1 символ = 7 бит). Это давало возможность применить 256 (128 при кодировке 7 бит) значений. Но, чтобы полноценно представить информацию этих 256 символов было недостаточно. Чтобы решить эту проблему, применялись такие методы:
Использование управляющих кодов для переключения языка. При использовании такого способа последовательность символов теряла смысл из-за отсутствия кода управления в начале, но все-таки нашел свое место в ZX-Spectrum и БК.
Использование UTF-16 и UTF-32 (несколько байт на символ). Такой метод не позволяет совмещать себя с другими областями, которые используются для работы с текстом. Из-за того, что символ “0” мог встретиться в абсолютно любом месте в строке, то это мешало работе библиотек.
Использование различных методов кодировок с плавающим значением символа (UTF-8). Такой метод приведет к проблемам в использовании прямого адреса символа, но позволяет совместить себя с устаревшими библиотеками.