

Работаем с потоками на Python
Многие часто говорят о том, как трудно использовать Python для многопоточной работы, указывая пальцами на то, что известно как глобальная блокировка интерпретатора (ласково называемая GIL), которая предотвращает одновременное выполнение нескольких потоков кода Python. Из-за этого модуль многопоточности Python ведет себя не совсем так, как вы ожидали бы, если бы вы не были разработчиком Python и пришли из других языков, таких как C++ или Java.
Необходимо ясно дать понять, что все еще можно писать код на Python, который работает одновременно или параллельно, и иметь разительную разницу в результирующей производительности, если принимать во внимание определенные вещи.
В этом уроке по параллелизму Python мы напишем небольшой скрипт Python для загрузки самых популярных изображений из Imgur. Мы начнем с версии, которая загружает изображения последовательно или по одному. В качестве предварительного условия вам придется зарегистрировать заявку на Imgur. Если у вас еще нет учетной записи Imgur, пожалуйста, сначала создайте ее. Скрипты в этих примерах потоковой передачи были протестированы с Python 3.6.4.
Начало работы с многопоточностью Python
Давайте начнем с создания модуля Python с именем download.py. Этот файл будет содержать все функции, необходимые для извлечения списка изображений и их загрузки. Мы разделим эти функции на три отдельные функции:
get_linksdownload_link
setup_download_dir
Третья функция, setup_download_dir, будет использоваться для создания каталога назначения загрузки, если он еще не существует.
API Imgur требует, чтобы HTTP — запросы содержали заголовок авторизации с идентификатором клиента. Вы можете найти этот идентификатор клиента на панели мониторинга приложения, которое вы зарегистрировали на Imgur, и ответ будет закодирован в формате JSON.
Мы можем использовать стандартную библиотеку Python JSON для его декодирования. Загрузка изображения-еще более простая задача, так как все, что вам нужно сделать, это получить изображение по его URL-адресу и записать его в файл.
Вот как выглядит скрипт:
importjson
import logging
importos
frompathlib import Path
fromurllib.request import urlopen, Requestlogger = logging.getLogger(__name__)
types = {‘image/jpeg’, ‘image/png’}
defget_links(client_id):
headers = {‘Авторизация’: ‘Client-ID {}’.format(client_id)}
req = Request(‘https://api.imgur.com/3/gallery/random/random/’, headers=headers, method=’GET’)
withurlopen(req) asresp:
data = json.loads(resp.read().decode(‘utf-8’))
return [item[‘link’] for item in data[‘data’] if ‘type’ in item and item[‘type’] in types]defdownload_link(directory, link):
download_path = directory / os.path.basename(link)
withurlopen(link) asimage, download_path.open(‘wb’) as f:
f.запись(image.read())
logger.info(‘Загружено %s’, link)defsetup_download_dir():
download_dir = Path(‘изображения’)
if not download_dir.exists():
download_dir.mkdir()
returndownload_dir
Далее нам нужно будет написать модуль, который будет использовать эти функции для загрузки изображений, одно за другим. Мы назовем это single.py. Это будет содержать основную функцию нашей первой, наивной версии загрузчика изображений Imgur.
Модуль получит идентификатор клиента Imgur в переменной окружения IMGUR_CLIENT_ID. Он вызовет setup_download_dir для создания каталога назначения загрузки. Наконец, он получит список изображений с помощью функции get_links, отфильтрует все URL-адреса GIF и альбомов, а затем использует download_link для загрузки и сохранения каждого из этих изображений на диск:
import logging
importos
from time import time
from download import setup_download_dir, get_links, download_linklogging.basicConfig(level=logging.ИНФОРМАЦИЯ, формат=’%(asctime)s — %(name)s — %(levelname)s — %(message)s’)
logger = logging.getLogger(__name__)def main():
ts = time()
client_id = os.getenv(‘IMGUR_CLIENT_ID’)
ifnotclient_id:
raise(«Не удалось найти переменную окружения IMGUR_CLIENT_ID!»)
download_dir = setup_download_dir()
links = get_links(client_id)
for links in links:
download_link(download_dir,link)
logging.info(‘Прошло %s секунд’, time() — ts)if __name__ == ‘__main__’:
main()
На обычном ноутбуке этот сценарий занял 19,4 секунды, чтобы загрузить 91 изображение. Пожалуйста, обратите внимание, что эти цифры могут варьироваться в зависимости от сети, в которой вы находитесь. 19,4 секунды-это не очень долго, но что, если мы захотим загрузить больше фотографий? Возможно, 900 изображений вместо 90.
При среднем значении 0,2 секунды на снимок 900 изображений заняли бы примерно 3 минуты. Для 9000 снимков это заняло бы 30 минут. Хорошая новость заключается в том, что, вводя параллелизм или параллелизм, мы можем значительно ускорить этот процесс.
Во всех последующих примерах кода будут показаны только операторы импорта, которые являются новыми и специфичными для этих примеров. Для удобства все эти скрипты Python можно найти в этом репозитории GitHub: https://github.com/volker48/python-concurrency
Параллелизм в Python: Пример потоковой передачи
Многопоточность-один из наиболее известных подходов к достижению параллелизма и параллелизма Python. Потоковая передача-это функция, обычно предоставляемая операционной системой. Потоки легче процессов и имеют одинаковое пространство памяти.
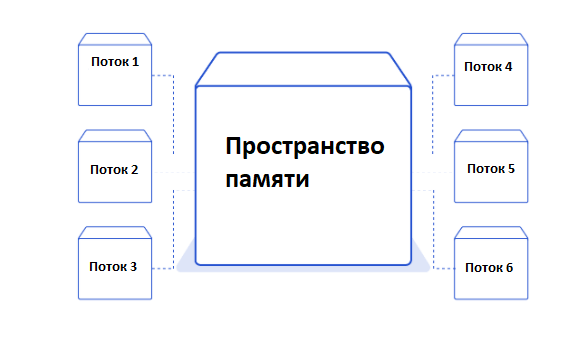
В этом примере Python threading мы напишем новый модуль для замены single.py. Этот модуль создаст пул из восьми потоков, в результате чего в общей сложности будет девять потоков, включая основной поток. Я выбрал восемь рабочих потоков, потому что мой компьютер имеет восемь процессорных ядер, и один рабочий поток на ядро казался хорошим числом для того, сколько потоков нужно запускать одновременно. На практике это число выбирается гораздо более тщательно, исходя из других факторов, таких как другие приложения и службы, работающие на той же машине.
Это почти то же самое, что и предыдущий, за исключением того, что теперь у нас есть новый класс DownloadWorker, который является потомком класса PythonThread. Был переопределен метод run, который запускает бесконечный цикл. На каждой итерации он вызывает self.queue.get (), чтобы попытаться получить URL-адрес из потокобезопасной очереди. Он блокируется до тех пор, пока в очереди не появится элемент для обработки работником.
Как только рабочий получает элемент из очереди, он вызывает тот же метод download_link, который использовался в предыдущем скрипте для загрузки изображения в каталог images. После завершения загрузки работник сигнализирует очереди, что эта задача выполнена. Это очень важно, потому что Очередь отслеживает, сколько задач было поставлено в очередь. Вызов queue.join() навсегда заблокирует основной поток, если рабочие не просигнализируют, что они выполнили задачу.
import logging
importos
from queue import Queue
from threading import Thread
from time import time
from download import setup_download_dir, get_links, download_linklogging.basicConfig(level=logging.INFO, format=’%(asctime)s — %(name)s — %(levelname)s — %(message)s’)
logger = logging.getLogger(__name__)
classDownloadWorker(Thread):
def __init__(self, queue):
Thread.__init__(self)
self.queue = queuedef run(self):
while True:
# Получить работу из очереди и развернуть кортеж
directory, link= self.queue.get()
try:
download_link(directory, link)
finally:
self.queue.task_done()def main():
ts = time()
client_id = os.getenv(‘IMGUR_CLIENT_ID’)
ifnotclient_id:
raise(«Не удалось найти переменную окружения IMGUR_CLIENT_ID!»)
download_dir = setup_download_dir()
links = get_links(client_id)
# Создайте очередь для связи с рабочими потоками
queue = queue()
# Создать 8 рабочих потоков
for x in(8):
worker = DownloadWorker(queue)
# Установка демона в True позволит основному потоку выйти, даже если рабочие блокируются
worker.daemon = True
worker.()
# Поместите задачи в очередь в виде кортежа
for link in links:
logger.info(‘Queueing {}’.format(link))
queue.put((download_dir, link))
# Заставляет основной поток ждать, пока очередь закончит обработку всех задач
queue.join()
logging.info(‘Took %s’, time() — ts)if __name__ == ‘__main__’:
main()
Запуск этого примера скрипта Pythonthreading на том же ноутбуке, что использовался ранее, приводит к времени загрузки 4,1 секунды! Это в 4,7 раза быстрее, чем в предыдущем примере. Хоть это и намного быстрее, стоит отметить, что только один поток выполнялся одновременно на протяжении всего этого процесса из-за GIL.
Таким образом, этот код является параллельным, но не параллельным. Причина, по которой он все еще быстрее, заключается в том, что это задача, связанная с вводом-выводом. Процессор почти не потеет при загрузке этих изображений, и большая часть времени тратится на ожидание сети. Вот почему многопоточностьPython может обеспечить значительное увеличение скорости. Процессор может переключаться между потоками всякий раз, когда один из них готов выполнить какую-либо работу.
Использование модуля threading в Python или любом другом интерпретируемом языке с GIL может фактически привести к снижению производительности. Если ваш код выполняет задачу, связанную с ЦП, например распаковку файлов gzip, использование модуля threading приведет к более медленному времени выполнения. Для задач, связанных с процессором и действительно параллельного выполнения, мы можем использовать модуль многопроцессорной обработки.
Параллелизм в Python. Пример 2: Порождение нескольких процессов
Модуль многопроцессорной обработки проще вставить, чем модуль потоковой обработки, так как нам не нужно добавлять класс, подобный примеру потоковой обработки Python. Единственные изменения, которые нам нужно внести, — это основная функция.
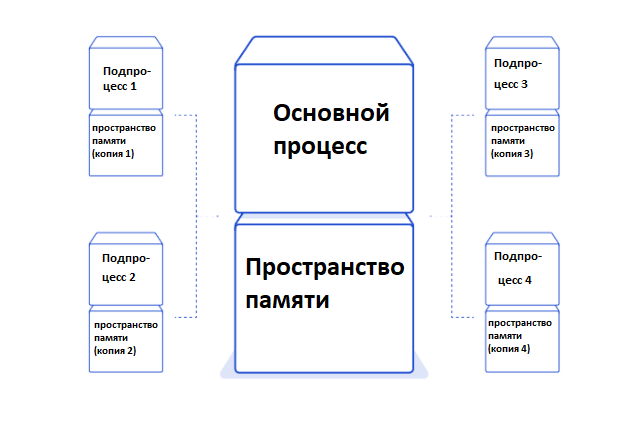
Чтобы использовать несколько процессов, мы создаем многопроцессорный пул. С помощью метода map, который он предоставляет, мы передадим список URL-адресов в пул, который, в свою очередь, породит восемь новых процессов и будет использовать каждый из них для параллельной загрузки изображений. Это истинный параллелизм, но он имеет свою цену.
Вся память сценария копируется в каждый порожденный подпроцесс. В этом простом примере это не имеет большого значения, но это может легко стать серьезными накладными расходами для нетривиальных программ.
import logging
importos
fromfunctools import partial
frommultiprocessing.pool import Pool
from time import timefrom download import setup_download_dir, get_links, download_link
logging.basicConfig(level=logging.DEBUG, format=’%(asctime)s — %(name)s — %(levelname)s — %(message)s’)
logging.getLogger(‘requests’).setLevel(logging.Critical)
logger = logging.getLogger(__name__)def main():
ts = time()
client_id = os.getenv(‘IMGUR_CLIENT_ID’)
ifnotclient_id:
raise(«Не удалось найти переменную окружения IMGUR_CLIENT_ID!»)
download_dir = setup_download_dir()
links = get_links(client_id)
download = partial(download_link, download_dir)
with Pool(4) as p:
p.map(download, links)
logging.info(‘Прошло %s секунд’, time() — ts)if __name__ == ‘__main__’:
main()
Параллелизм в Python. Пример 3: Распределение между несколькими рабочими
Модули потоковой обработки и многопроцессорной обработки отлично подходят для скриптов, запущенных на вашем персональном компьютере. Что вы должны делать, если хотите, чтобы работа выполнялась на другой машине, или вам нужно масштабировать ее до большего количества, чем может обработать процессор на одной машине? Отличный пример использования для этого-длительные внутренние задачи для веб-приложений.
Если у вас есть какие-то длительные задачи, вы не хотите раскручивать кучу подпроцессов или потоков на одной машине, которые должны выполнять остальную часть кода вашего приложения. Это приведет к снижению производительности вашего приложения для всех ваших пользователей. Что было бы здорово, так это иметь возможность выполнять эти задания на другой машине или на многих других машинах.
Отличная библиотека Python для этой задачи-RQ, очень простая, но мощная библиотека. Сначала вы ставите в очередь функцию и ее аргументы, используя библиотеку. Это маринует представление вызова функции, которое затем добавляется в список Redis. Постановка задания в очередь-это первый шаг, но пока ничего не даст. Нам также нужен хотя бы один работник, чтобы слушать эту очередь заданий.
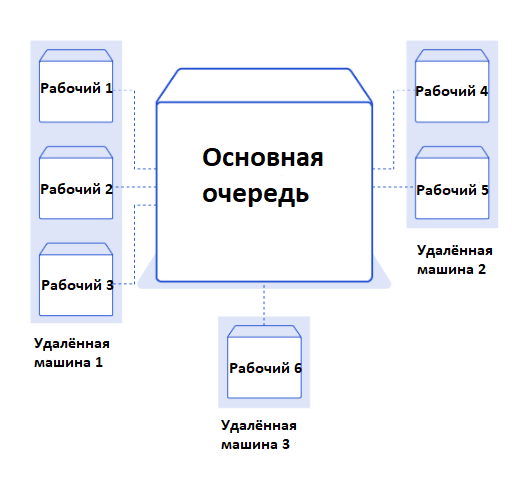
Первым шагом является установка и запуск сервера Redis на вашем компьютере или получение доступа к работающему серверу Redis. После этого в существующий код вносится лишь несколько небольших изменений.
Сначала мы создаем экземпляр очереди RQ и передаем ему экземпляр сервера Redis из библиотеки redis-py. Затем, вместо того чтобы просто вызывать наш метод download_link, мы вызываем q.enqueue(download_link, download_dir, link). Метод enqueue принимает функцию в качестве своего первого аргумента, а затем любые другие аргументы или аргументы ключевого слова передаются этой функции при фактическом выполнении задания.
Последний шаг, который нам нужно сделать, — это запустить несколько рабочих. RQ предоставляет удобный скрипт для запуска рабочих в очереди по умолчанию. Просто запустите rqworker в окне терминала, и он запустит рабочий процесс прослушивания очереди по умолчанию. Пожалуйста, убедитесь, что ваш текущий рабочий каталог совпадает с тем, в котором находятся скрипты. Если вы хотите прослушать другую очередь, вы можете запустить rqworkerqueue_name, и он будет прослушивать эту именованную очередь.
Самое замечательное в RQ то, что до тех пор, пока вы можете подключаться к Redis, вы можете запускать столько рабочих, сколько захотите, на любом количестве различных машин, сколько захотите; таким образом, это очень легко масштабировать по мере роста вашего приложения. Вот источник для версии RQ:
mport logging
importosfromredis import Redis
fromrqimportQueue
from download import setup_download_dir, get_links, download_link
logging.basicConfig(level=logging.DEBUG, format=’%(asctime)s — %(name)s — %(levelname)s — %(message)s’)
logging.getLogger(‘requests’).setLevel(logging.CRITICAL)
logger = logging.getLogger(__name__)def main():
client_id = os.getenv(‘IMGUR_CLIENT_ID’)
ifnotclient_id:
raise(«Не удалось найти переменную окружения IMGUR_CLIENT_ID!»)
download_dir = setup_download_dir()
links = get_links(client_id)
q = queue(connection=Redis(host=’localhost’, port=6379))
for link in links:
q.enqueue(download_link, download_dir, link)if __name__ == ‘__main__’:
main()
Однако RQ-это не единственное решение очереди заданий Python. RQ прост в использовании и очень хорошо охватывает простые случаи использования, но если требуются более продвинутые опции, можно использовать другие решения очереди Python 3 (например, Сельдерей).
Многопоточность Python против многопроцессорной обработки
Многопроцессорность проще просто сбросить, чем потоковую обработку, но имеет более высокие накладные расходы на память. Если ваш код привязан к процессору, то многопроцессорная обработка, скорее всего, будет лучшим выбором—особенно если целевая машина имеет несколько ядер или процессоров. Для веб-приложений и когда вам нужно масштабировать работу на нескольких машинах, RQ будет лучше для вас.
Заключение
Закрепим полученные знания:
Что такое поток в Python?
Поток-это легкий процесс или задача. Поток-это один из способов добавить параллелизм в ваши программы. Если ваше приложение Python использует несколько потоков и вы смотрите на процессы, запущенные в вашей ОС, вы увидите только одну запись для вашего скрипта, даже если он работает в нескольких потоках.
В чем разница между потоковой обработкой Python и многопроцессорной обработкой?
При потоковой обработке параллелизм достигается с помощью нескольких потоков, но из-за GIL одновременно может выполняться только один поток. При многопроцессорной обработке исходный процесс разветвляется на несколько дочерних процессов в обход GIL. Каждый дочерний процесс будет иметь копию всей памяти программы.
Как связаны многопоточность и многопроцессорность Python?
Как многопоточность, так и многопроцессорность позволяют Python-коду работать одновременно. Только многопроцессорная обработка позволит вашему коду быть по-настоящему параллельным. Однако если ваш код является IO-тяжелым (например, HTTP-запросы), то многопоточность все равно, вероятно, ускорит ваш код.


Мне кажется что тема не до конца раскрыта…
Добрый день. На самом деле эта тема очень большая, за одну статью ее никак не раскрыть. Но мы будем публиковать новые материалы в ближайшее время, поэтому следите за нашими обновлениями.