
Работа с базами данных в Python
На языке Питон пишутся различные программы. Им часто нужно хранить какую-то информацию или использовать ее. Десктопным приложениям может быть достаточно файла формата json. Для веб приложений или программ работающих с большими объемами данных такой формат не подходит. Большие объемы данных хранятся в специальных форматах баз данных.
В веб-разработке часто используют реляционные базы данных. В питоне есть несколько модулей для взаимодействия с ними.
Структура данных
Реляционные базы данных состоят из таблиц, между которыми может быть установлена связь. Перед созданием базы данных следует нормализовать ее структуру, убрать логическую избыточность. Для этого следует проанализировать данные и разбить их на таблицы. В базе не должно быть повторений групп данных.
Структура данных – это таблицы. Таблица состоит из нескольких столбцов, каждый из которых содержит информацию определенного типа. Тип данных в ячейке – это строка, числовое значение, дата и так далее. Каждая таблица имеет уникальное, в пределах базы, имя. Внутри таблицы у столбцов имена так же не повторяются.
Один из столбцов – это ключ (primary key). Ключ обязателен для каждой таблицы, принцип выбора похож на задание ключей в словарях в питоне, он должен быть уникальным. Как правило, в базах данных используют в качестве primary key целые числа.
Рассматривать работу с базами данных будем на примере создания и изменения данных для книжного приложения. Есть книги, издательства и авторы между ними существует определенная связь.
Связь таблиц в базе
Связь данных между таблицами может быть нескольких типов. Это зависит в первую очередь от структуры данных. При создании новой таблицы параметром ее ячейки вместо обычного типа данных может быть ссылка на строку в другой таблице. Как правило, роль такой ссылки играет ключ.
Связь один к одному
Самый простой вид связи. В созданной таблице не могут повторяться ссылки на другую таблицу. Новую таблицу можно рассматривать как дополнение к существующей. Например, издательство может создать таблицу эксклюзивных книг. Заполнять для всех книг эту таблицу может быть нерационально, поэтому вместо добавления столбца есть смысл создать дополнительную таблицу. В этой таблице оба столбца должны хранить уникальные значения.
Связь один к многим
Многие базы данных не могут обойтись без этой связи. Например, если мы захотим иметь данные для связи с авторами, то можно создать таблицу с email адресами или номерами телефонов. При этом у автора может быть набор электронных почт или пара мобильных номеров, но с одного email разные авторы писать не могут.
Связь многие ко многим
Для соединения подобного типа потребуется дополнительная таблица. Таблица состоит из трех столбцов: ее собственный ключ, ключ от первой таблицы и ключ от второй таблицы.
При внесении изменений в базу автоматически проверяется ссылочная целостность. При создании записи происходит проверка внешних ключей. При удалении записи, если на нее существовали ссылки, то используется один из трех сценариев: прекращение операции, каскадное удаление или замена этих ссылок на NULL.
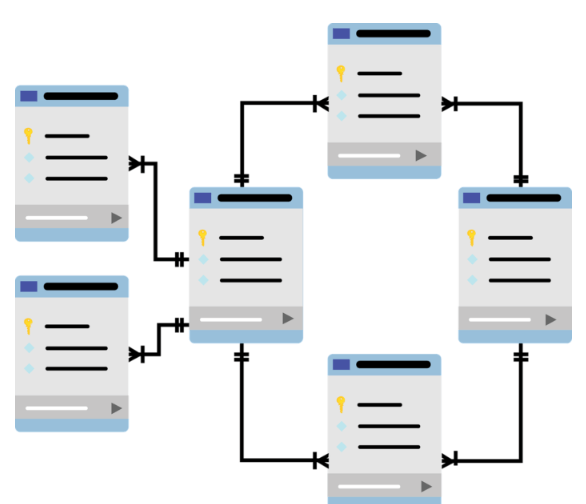
Структура примера
Для авторов, книг и издательств будет использовано три отдельных таблицы. Связь между книгами и издательствами, книгами и авторами – многие ко многим. Дополнительно есть таблица для контактов и список уникальных книг.
Авторы
- primary key
- имя
- фамилия
Книги
- primary key
- название
- описание
Издательства
- primary key
- название
Контакты
- primary key
- номер телефона
- автор, ссылка на таблицу авторы
Уникальные книги
- primary key
- книга, ссылка на таблицу книги
Связь книг и издательств
- primary key
- книга, ссылка на таблицу книги
- издательство, ссылка на таблицу издательства
Связь книг и авторов
- primary key
- книга, ссылка на таблицу книги
- автор, ссылка на таблицу авторы
Язык SQL
Язык запросов разработанный специально для управления базами данных. Используется для доступа и редактирования информации в таких базах данных как SQLite, PostgeSQL, MySQL и так далее. Базы данных отличаются по возможностям и функционалу.
Создание простой базы данных SQLite3
SQLite – это простая база данных. Для управления информацией в ней используется SQL. Использовать этот язык можно из консоли или специального приложения, например sqlitebroweser (вкладка Execute SQL).
Традиционно все команды записываются заглавными буквами, но они не зависят от регистра и запись строчными буквами допустима. Каждая команда заканчивается точкой с запятой, поэтому может быть записана в несколько строк. Имена таблиц или столбцов не должны содержать пробелы и иметь длину более 128 символов. Имена не должны совпадать с командами используемыми базой данных.
SQLite типы данных
При создании таблицы для каждого столбца указывается тип данных, которые могут быть в него записаны. Дополнительными параметрами можно задать: уникальность, обязательность заполнения при внесении в базу, указать какой именно столбец является ключом.
Основные классы, с которыми работает SQLite:
- NULL – отображается как простая ячейка;
- INTEGER – целые числа со знаком;
- REAL – число с плавающей запятой;
- TEXT – текстовая строка;
- BLOB – блок данных.
В этой базе отсутствуют определенные типы данных, например boolean или формат для хранения даты. Подобные данные можно сохранять в формате строки или как число.
Создание таблиц
Создать таблицу можно командой CREATE TABLE. После команды указывается имя, а в скобках через запятую перечисляются названия столбцов и опции для них.
Пример создание таблицы на языке SQL:
CREATE TABLE author (
author_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
first_name VARCHAR,
last_name VARCHAR
);
После этого в базе должна появиться таблица с именем “author”. В ней три столбца: целочисленный ключ author_id, который не может быть нулем и два столбца для строк.
Если в таблице должны быть ссылки на другие таблицы, то это указывают дополнительной строкой:
CREATE TABLE contacts (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
author_id INTEGER NOT NULL,
email VARCHAR,
FOREIGN KEY (author_id) REFERENCES author (author_id)
);
Особенность этой таблицы в том, что при создании и изменении записей в базе, значения столбца author_id будут сверяться со значениями ключей в таблице author.
Создание дополнительной таблицы для связи многие ко многим авторов и издательств:
CREATE TABLE author_publisher (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
author_id INTEGER REFERENCES author,
publisher_id INTEGER REFERENCES publisher
);
Манипуляции данными
После того как таблица была создана следует заполнить ее. Добавлять в таблицу строки можно командой “INSERT <название таблицы> (<имена столбцов через запятую>) VALUES (<данные через запятую>);”.
Пример добавления одной записи в таблицу с авторами:
INSERT INTO author
(first_name, last_name)
VALUES (‘Paul’, ‘Mendez’);
Изменять значение строки можно следующим образом:
UPDATE author
SET first_name = ‘Richard’, last_name = ‘Bachman’
WHERE first_name = ‘Stephen’ AND last_name = ‘King’;
Удалить строку можно командой:
DELETE FROM author
WHERE first_name = ‘Paul’
AND last_name = ‘Mendez’;
Конструкция “WHERE <условие>” работает как фильтр. Для сортировки данных используется команда ORDER BY.
Просмотр данных
Просмотреть всю таблицу целиком:
SELECT * FROM author;
Если из таблицы нужно извлечь только определенные столбцы, то вместо “*” перечисляют их названия.
Использование Python
В языке питон есть множество модулей для работы с базами данных. В этой статье рассмотрим поддерживающие DB-API модули для работы с тремя базами данных.
DB-API 2.0
Разработчики питона создали спецификацию для упрощения миграции с одной базы на другую. Подробности db-api описаны PEP 249. Это стандарт для разработчиков библиотек. Набор методов, которые должны присутствовать в библиотеке, чтобы она соответствовала стандарту:
- .close() – закрывает соединение.
- .commit() – подтверждает, ожидающую этого, транзакцию. Если нет незавершенных транзакций, то ничего не делает.
- .connect(path) – конструктор, который создает соединение. Возвращает объект, с которым работают остальные методы.
- .cursor() – возвращает объект, который будет использован для выполнения запросов.
- .rollback() – откатывает, ожидающую подтверждения, транзакцию. Если нет незавершенных транзакций, то ничего не делает.
Набор методов и параметров для объекта курсора:
- .arraysize – число строк, которое возвращает метод fetchmany, если его вызывать без параметра.
- .close() – закрывает курсор.
- .description – параметр доступен только для чтения, он описывает очередной столбец курсора.
- .execute(sql, param) – строка sql содержит текст запроса, а через param передают параметры, которые нужны строке.
- .executemany(sql, seq_of_param) – здесь sql это список строк для выполнения.
- .fetchall() – возвращает все не извлеченные строки.
- .fetchmany(size) – возвращает указанное число строк, по умолчанию используется size равное .arraysize.
- .fetchone() – возвращает одну строку, если запросы закончились – вернет None. Если набор результатов отсутствует – вызовет исключение.
- .rowcount – считает выполненные операции.
Стандарт содержит так же описания ошибок, которые могут вернуть методы. Есть глобальные переменные, например paramstyle, которая определяет, какой стиль используется при указании параметров в строках.
Модули, которые удовлетворяют стандарту db-api 2.0
Для популярных баз данных есть библиотеки, которые полностью соответствуют этому стандарту. Для базы данных SQLite – это рассмотренная выше библиотека sqlite3, при использовании PostgreSQL или MySQL модуль потребуется установить. PostgeSQL работает с модулем psycopg2, для MySQL подойдет mysql.connector.
Работа в SQLite с использованием модуля sqlite3
В стандартный пакет питона входит библиотека sqlite3 для работы с этой базой данных. SQLite – это простая база, не требующая запуска дополнительных программ. Она не имеет встроенного механизма аутентификации.
Рассмотрим создание базы данных при помощи этой библиотеки. Она позволяет быстро добавлять, изменять или удалять строки в таблицу при помощи циклов.
Соединение с базой данных:
# загрузка модуля
import sqlite3# создание соединения
conn = sqlite3.connect(“books_app.db”)
cursor = conn.cursor()# здесь будут расположены запросы пользователя к базе
# Вместо этого комментария можно вставить код приведенный ниже# завершение работы с базой
cursor.close()
conn.close()
Создание новой таблицы:
# код SQL команды для создания таблицы
create_author = ‘’’CREATE TABLE author (
author_id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
first_name VARCHAR,
last_name VARCHAR
)’’’# SQL команда помещается в команду execute
cursor.execute(create_author)# Эта команда подтверждает транзакцию
conn.commit()
Заполнение таблицы:
add_new = ‘’’INSERT INTO author
(first_name, last_name)
VALUES (‘Paul’, ‘Mendez’)‘’’
cursor.execute(add_new)
conn.commit()
Удаление строк:
sql_del = “””DELETE FROM author
WHERE first_name = ‘Paul’
AND last_name = ‘Mendez’”””
cursor.execute(sql_del)
conn.commit()
Изменение значений:
sql_change = “””UPDATE author
SET first_name = ‘Richard’, last_name = ‘Bachman’
WHERE first_name = ‘Stephen’ AND last_name = ‘King’”””
cursor.execute(sql_change)
conn.commit()
Для передачи пользовательского ввода при заполнении таблиц нельзя складывать строки или использовать форматирование строк, так как это может послужить уязвимостью типа SQL-инъекций. Все необходимые параметры должны быть переданы во второй переменной функции execute.
Пример использования:
# C подстановкой по порядку на места знаков вопросов:
cursor.execute(«SELECT first_name FROM author ORDER BY first_name LIMIT ?», (‘2’))# И с использованием именованных замен:
cursor.execute(«SELECT first_name from author ORDER BY first_name LIMIT :limit», {«limit»: 3})
Просмотр данных из базы:
cursor.execute(«SELECT last_name FROM author ORDER BY last_name LIMIT 3»)
results = cursor.fetchall()
print(results)
В переменной results окажется список запрошенных командой данных. Выбрать одну запись можно командой fetchone. Выбрать определенное количество записей командой fetchmany. fetchall собирает все данные, которые собраны в объект курсор командой execute.
Установка модулей
Для python написано много модулей и далеко не все включены в стандартную версию. Для установки модуля можно воспользоваться вспомогательной программой pip. Процесс установки запускается командой из консоли “pip install -<опция> <имя пакета>”. Пример команды для установки модуля для MySQL:
pip install mysql-connector-python
Программы для работы с модулями нужно установить в систему дополнительно. PIP работает с Windows, OS X и Linux. Чтобы установить его в Windows нужно скачать установочный скрипт get_pip.py. Отрыть консоль или командную строку и перейти в папку, где размещен скрипт. После этого выполнить команду “python get-pip.py”.
MySQL
Одна из самых популярных серверных баз данных. Программы общаются с ней используя процесс-демон. Для доступа к базе потребуется: имя пользователя, пароль, адрес или имя хоста. База поддерживает различные типы данных: целые числа, числа с плавающей точкой, форматы для времени и даты, строки, блоки данных, множества и перечисления.
Работа с MySQL при помощи mysql.connector
Преимуществом DB-API является, то что работа с базой, с точки зрения кода на питон значительных отличий от работы с SQLite иметь не будет. Рассмотрим работу модуля mysql-connector-python.
Если база не создана, то можно использовать соединение для создания новой базы:
import mysql.connector
conn = mysql.connector.connect(
host=”localhost”,
user=”root”,
passwd=””
)
cursor = conn.cursor()
cursor.execute(“CREATE BASE sm_app”)
После создания базы, следует подключиться к ней:
import mysql.connector
conn = mysql.connector.connect(
host=”localhost”,
user=”root”,
passwd=””,
database=”sm_app”
)
В отличие от SQLite для соединения с базой конструктору нужно передать имя или адрес хоста, пользователя, пароль, название базы. В остальном значительной разницы для питона не будет. Объект курсора можно создать так же как и для sqlite3, для создания таблиц и работы с данными в них используются те же функции.
PostgreSQL
PostgerSQL полностью соответствует стандарту SQL и поддерживает концепцию ACID. Для нее существует много инструментов. Как и MySQL, Postgres – это серверная база данных, которая использует процесс-демон для работы с приложениями. В базе можно сохранять большинство типов данных.
Работа с PostgreSQL при помощи psycopg2
Как и для mysql, для psycopg2 основным отличием от sqlite3 будет подключение к базе. Для создания соединения потребуется имя пользователя, пароль, адрес хоста и название базы.
Для начала создадим базу:
import psycopg2
conn = psycopg2.connect(
database=»postgres»,
user=»postgres»,
password=»abc123″,
host=»127.0.0.1″,
port=»5432″
)
conn.autocommit = True
cursor = conn.cursor()
cursor.execute(“CREATE BASE sm_app”)
После этого можно подключиться к созданной базе:
conn = psycopg2.connect(
database=»sm_app»,
user=»postgres»,
password=»abc123″,
host=»127.0.0.1″,
port=»5432″
)
Дальнейшие действия похожи на описанные для SQLite.
Итоги
В статье мы рассмотрели работу с базами данных при помощи библиотек питона поддерживающих DB-API. Стандарт позволяет работать с разными модулями без подробного изучения документации для каждого отельного модуля. Это обеспечивает возможность быстрого переноса базы в случае необходимости. Использование стандарта DB-API позволяет работать с различными базами данных, но подразумевает понимание языка SQL.
Помимо db-api в разработке используются и другие инструменты. Популярные фреймворки чаще используют иной подход. Например, библиотека SQLAlchemy, часто используемая совместно с Flask, умеет работать с несколькими базами данных. Записи базы данных обрабатываются как объекты языка. Такой подход позволяет убрать код SQL из питона и работать с привычными для разработчика объектами.


